Install
정의
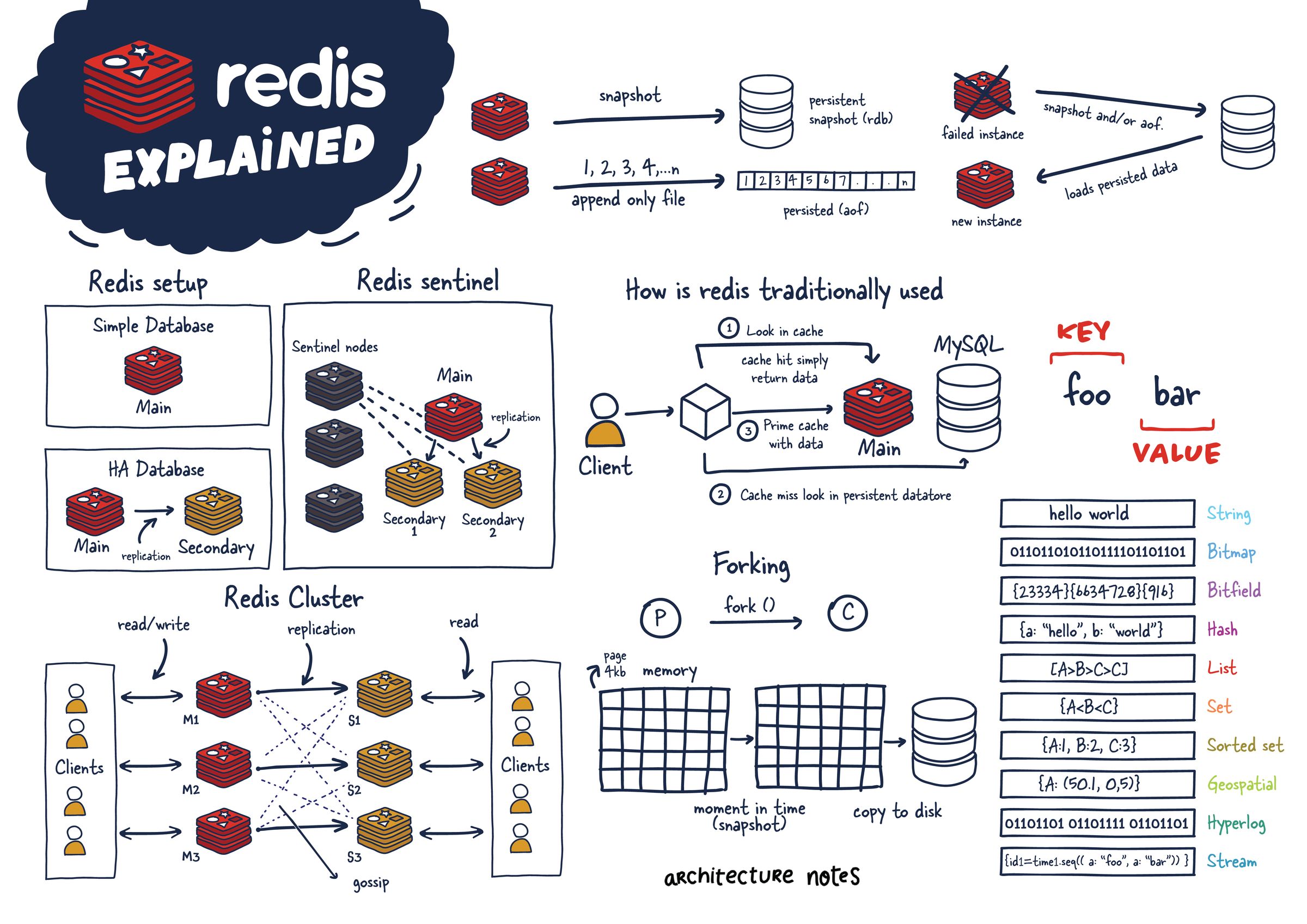
Remote Dictionary Server의 약자로, 메모리 기반의 key-value 구조 데이터 관리 시스템이다.
오픈소스이며, 속도가 빠르다는 장점이 있다.
타입
Redis
1 main node : no redundancy
replication (main-secondary) : 1 main node + 1 or more secondary node
Redis Sentinel
1 main node + 1 or more secondary node + 3 or more sentinel node
Redis Cluster
3 or more main node + 3 or more secondary node with replication
https://architecturenotes.co/content/images/size/w2400/2022/08/Redis-v2-01-1.jpg
{kind=link}

Redis 설치
주의 : redis docker image는 유명한것이 2가지가 있다.
둘다 써도 무방하다.
redis는 환경 변수를 지원을 안하고 conf 파일을 지원한다.
bitnami/redis는 환경 변수를 지원한다.
bitnami/redis를 사용한다. 버전은 다음에서 찾을수 있다. https://hub.docker.com/r/bitnami/redis/tags
single main node
동작확인됫다 이방식은 redundancy가 없다. 그리고 트래픽이 많아지면 1개의 서버가 모든 트래픽을 받아야한다. 그래서 replication을 사용한다.
replication (main-secondary)


이제 replica-1에서 확인해보자.
마스터에서 입력한 값을 Secondary가 가지고 있다.
프로그램은 Secondary 연결하여 데이터를 가져갈수 있다.
데이터의 복제가 잇어서 한노드가 망가지더라도 데이터가 유실되지 않는다. 그러나 수동으로 main를 변경해야한다. 이걸 자동으로 해주는 것이 Redis Sentinel이다.
Redis Sentinel 설치

확인해보자.
Redis Cluster 설치

3 master 와 3 secondary로 구성되었다.

cluster_state : 클러스터가 정상인 상태입니다. cluster_slots_assigned : 클러스터에 할당된 슬롯 개수 입니다. cluster_slots_ok : 현재 구동된 클러스터에 할당된 슬롯 개수 입니다. (특정 노드 다운 시, 해당 노드의 슬롯 개수가 빠지게 됩니다.) cluster_slots_fail : 인식하지 못하는 슬롯 개수입니다. cluster_known_nodes : 클러스터에 구성된 모든 노드 수 입니다. cluster_size : 클러스터 마스터 노드 수 입니다.

이제 아무 노드나 접속해서 테스트해보자.
잘 된다.
Type별 특징
Redis - standalone
simple
no redundancy
no failover
Redis - replication
HA(High Availability)를 위한 구조
Read Performance(읽기 성능) 향상
Fault tolerance
Main instance는 복제 ID와 offset을 가지고 있다.(Replication ID, offset)
Main과 Secondary 가 같은 replication ID를 가지고 있고 offset이 다른 경우 동기화가 필요
offset 값은 main Redis가 deployment(배포)될 때마다 일어난다
두 요소는 복제가 계속될 수 있는 시점을 찾는데도 도움이 되며, Secondary main instance 간 동기화를 확인할 수 있다.
RDB snapshot이나, 복제본을 보내어 동기화를 하는 등 Main과 secondary를 sync할 작업이 발생한다.
Replication ID: instance가 Main으로 승격되거나 Main으로서 다시 처음부터 시작하게 된다면, replication ID 변경
클라이언트 요청시 Zookeeper처럼 현재 기본 인스턴스가 무엇인지를 알려준다.클라언트는 이정보를 사용하여 다시 정보 요청한다.
Redis의 복제는 비동기식
Redis - sentinel
Main/Secondary 제대로 동작하는지 지속적 Monitoring
Automatic Failover
Notification : failover되었을 때 Notification 보낼 수 있다
과반 수 이상의 sentinel이 Master 장애를 감지하면 Slave 중 하나를 Master로 승격시키고 기존의 Master는 Slave로 강등시킨다
Slave가 여러개 있을 경우 Slave가 새로운 Master로부터 데이터를 받을 수 있도록 자동으로 재구성된다.
Quorum : 몇 개의 Sentinel이 Redis의 장애 발생을 감지해야 장애라고 판별하는지를 결정하는 기준 값. redis replica의 과반 수 이상으로 설정한다.
Sentinel은 1차 복제만 Master 후보에 오를 수 있다. (복제 서버의 복제 서버는 불가능)
1차 복제 서버 중 replica-priority 값이 가장 작은 서버가 마스터에 선정된다. 0으로 설정하면 master로 승격 불가능하고 동일한 값이 있을 땐 엔진에서 선택한다.
안정적 운영을 위해 3개 이상의 sentinel을 만드는 것을 권장하는데, 서로 물리적으로 영향받지 않는 컴퓨터나 가상 머신에 설치되는 것이 좋다.
sentienl은 내부적으로 redis 의 Pub/Sub 기능을 사용해서 서로 정보를 주고 받는다.
센티널 + 레디스 구조의 분산 시스템은 레디스가 비동기 복제를 사용하기 때문에 장애가 발생하는 동안 썼던 내용들이 유지됨을 보장할 수 없다.
Sentinel을 Redis와 동일한 Node에 구성해도 되고, 별도로 구성해도 된다.
클라이언트는 레디스 Main의 주소를 알아내기 위해 센티널에 연결한다. sentinel이 Main 주소를 보내준다. 장애 조치가 발생하면 sentinel은 새 Main주소를 알려준다.
쿼럼(Quorum) : 센티널이 장애를 감지하기 위한 최소한의 센티널 수
number of serverQuorumavailable Fail1
1
0
2
2
0
3
2
1
4
3
1
4
3
1
5
3
2
5개의 서버가 되면 2개가 fail해도 작동한다. 그러므로 5개를 추천한다.
failover 감지 방법
SDOWN : Subjectively down(주관적 다운) sentinel에서 주기적으로 Master에게 보내는 PING과 INFO 명령의 응답이 3초 동안 오지 않으면 주관적 다운으로 인지 센티널 한 대에서 판단한 것으로, 주관적 다운만으로는 장애조치를 진행하지 않는다.
ODOWN : Objectively down(객관적 다운) 설정한 quorum 이상의 sentinel에서 해당 Master가 다운되었다고 인지하면 객관적 다운으로 인정하고 장애 조치를 진행합니다.
redis-cluster
Automatic Failover
sharding
main이 죽을 경우 Secondary중 하나가 main로 승격된다 → 중단없는 서비스 제공
gossip Protocol : 각 Redis는 다른 Redis들과 직접 연결하여 상태 정보를 통신
기존 main이 다시 살아나면 Secondary가 된다
Multi-Main, Multi-Secondary 구조
노드를 추가/삭제할 때 운영 중단 없이 Hash slot을 재구성할 수 있다
과반수 이상의 노드가 fail되면 cluster가 망가진다
data 정합성이 맞지않으면 Master의 Data를 기준으로 정합성을 맞춘다.
cluster redis는 2개의 포트가 필요하다 (클라이언트를 위한 포트, 노드 간 통신 버스 포트)
클라이언트가 redis에 데이터를 요청했을 때, 올바르지 않은 master node에 요청하면 해당 데이터가 저장된 위치를 알려주고 client에게 알려주고 client는 제대로 된 주소에 다시 요청한다
16K hashslot을 이용하여 데이터가 cluster 사이에 적절히 분배될 수 있도록 돕는다.
영속성
RDB Files
Snapshot
Snapshot 이후 데이터는 상실
AOF 보다메모리에 로드되는 속도 빠르다.
AOF (Append Only File)
서버 시작 시, 다시 재생될 서버가 수신하는 모든 쓰기 작업을 기록하여 원본 데이터 세트를 재구성한다.
작업이 발생하면, 로그에 버퍼링된다.
압축되지 않아 RDB(Redis DataBase)보다 훨씬 더 많은 디스크를 사용할 수 있다
서버 재시작시에 기존데이터 보관이 필요한경우에 좋을거같다. replication이나 sentinel을 설정한경우 재부팅후 자동 복제 일어나서 필요없음.
Kubernetes 에서 배포
이제 kubernetes에서 배포해보자.
argocd를 사용하므로 subchart를 만들자.
helm chart versin을 정확시 적어 줍니다.
argocd로 배포하자.
replica갯수만큰 pod가 생성이 됩니다 그리고 이 pod에는 redis와 sentinel이 sidecar로 생성됩니다.
replica가 3개면 3개의 pod가 생성됩니다. 그리고 그중 하나가 master가 되고 나머지 2개는 slave가 됩니다.
전체 pod에 sentinel도 동시에 설치되므로 quorum을 3로 설정하면 (2개의 pod가 망가져도 sentinel 클러스터 유지)하려면 5개의 replica를 설정해야합니다.
추가 설정은 다음에서 확인하세요.
https://artifacthub.io/packages/helm/bitnami/redis
참고
Last updated