> For the complete documentation index, see [llms.txt](https://teamsmiley.gitbook.io/devops/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://teamsmiley.gitbook.io/devops/ai/langchain/rag.md).
# rag
## 개요
1. 전처리
2. 서비스
두개의 단계로 나눠진다.
### 전처리
전처리를 해서 가지고잇는 모든 문서를 embed해서 디비에 넣어둔다.

### 서비스
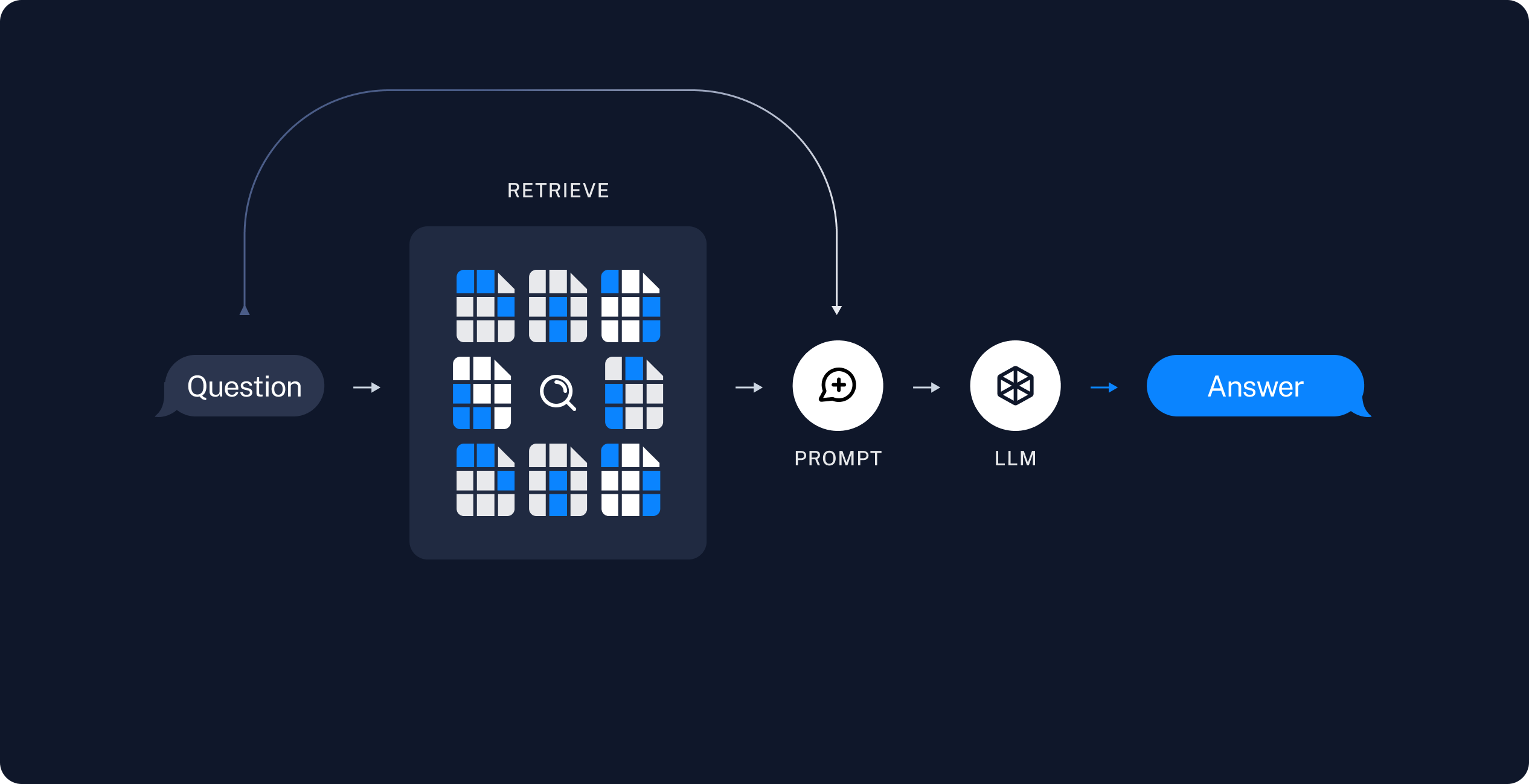
### 정리

## Document Loader
많은것중에 알아서 골라쓰면 된다.
일단 난 이걸로 선택
```python
%pip install --user -Uq unstructured
```
```python
from dotenv import load_dotenv
load_dotenv()
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import UnstructuredMarkdownLoader
loader = UnstructuredMarkdownLoader("files/kubernetes_hardening_guidance.md")
docs = loader.load()
docs
```
```python
len(docs)
```
## Document Splitter
도큐먼트 1개로 로드가 된다. 이 문서를 다 llm으로 보내도 되나 비용문제가 발생한다.
그리고 llm에서 최대 크기가 잇어서 전부다 한꺼번에 보내지 못한다.
필요없는부분까지 보내서 비용을 내는것보다 짤라서 필요한 부분만 보내면 더 좋을거같다.
```python
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter()
docs = loader.load_and_split(text_splitter=splitter)
docs
```
```python
len(docs)
```
14개로 짤라진걸 볼수 있다.
더 많이 잘라보자.
```python
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=200
)
docs = loader.load_and_split(text_splitter=splitter)
docs
```
```python
len(docs)
```
14개가 2482로 늘어났다. 근데 문장이 짤림.. llm이 이해를 못함.
overlap을 사용하자.
```python
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=50,
separators=["\n", "\r\n"],
length_function=len,
)
docs = loader.load_and_split(text_splitter=splitter)
docs
```
```python
len(docs)
```
openai는 length를 사용하지 않고 token을 사용한다.
토큰과 character가 다른걸 알수있다.
우리는 문서를 token단위로 이해해야할 필요가 있다.
링크에서 tikoken 패키지를 추천한다.
사용하자.
```python
%pip install --user -Uq tiktoken
```
```python
from langchain.text_splitter import CharacterTextSplitter
splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=200,
chunk_overlap=50,
separator="\n",
)
docs = loader.load_and_split(text_splitter=splitter)
len(docs)
```
문서가 잘 나눠졌다. 이제 임베딩을 해서 디비에 넣어보자.
## Embedding 하기
문서를 숫자로 바꿔서 디비에 넣을준비를 하는것임 이 숫자를 기준으로 유사도를 검색한다.
주의사항은 임베딩 방식을 지금 결정하면 나중에 query를 할때도 같은 방식으로 해야한다.
openai embeding을 이용합니다.다른것들도 있으니 찾아서 보시요
을 참고하시요
난 일단 몰라도 되는거같아서 바로 코드로 진행
OpenAI Embedding을 사용하자.
```python
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
text = "This is a test document."
vector = embeddings.embed_query(text)
vector
```
```python
len(vector)
```
```python
doc_result = embeddings.embed_documents([text])
doc_result[0][:5]
```
```python
print(len(doc_result))
len(doc_result[0])
```
```python
embeddings = OpenAIEmbeddings(
model="text-embedding-3-large", dimensions=1024)
```
```python
len(embeddings.embed_documents([text])[0])
```
## Embedding을 디비(FAISS) 에 넣기
임베딩을 해서 FAISS 에 입력하기
```python
%pip install --user -Uq faiss-cpu
# %pip install --user -Uq faiss-gpu
```
```python
from langchain_openai import OpenAIEmbeddings
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.storage import LocalFileStore
from langchain_community.document_loaders import UnstructuredMarkdownLoader
splitter = CharacterTextSplitter.from_tiktoken_encoder(
separator="\n",
chunk_size=600,
chunk_overlap=100,
)
loader = UnstructuredMarkdownLoader("files/kubernetes_hardening_guidance.md")
docs = loader.load_and_split(text_splitter=splitter)
```
```python
from langchain.vectorstores import FAISS
embeddings = OpenAIEmbeddings()
# 임베딩을 해서 디비에 넣는다.
vectorstore = FAISS.from_documents(docs, embeddings)
```
```python
results = vectorstore.similarity_search("누구에게 이 가이드를 추천하는가?")
results
```
유사도 검사를 해서 문장을 잘 찾아온다. 이걸 프롬프트로 llm에 보내면 된다.
보통 3개나 5개가 좋다고한다.
## Embedding cache
할때마다 비용이 발생한다.
디비에 입력한 것은 로컬 드라이브에 cache를 하자. 그러면 openai에 다시 요청하지 않아서 요금이 줄어든다.
```python
# caching
from langchain.embeddings import CacheBackedEmbeddings
embeddings = OpenAIEmbeddings()
cache_dir = LocalFileStore("./cache/")
cached_embeddings = CacheBackedEmbeddings.from_bytes_store(embeddings, cache_dir)
# vectorstore = FAISS.from_documents(docs, embeddings)
vectorstore = FAISS.from_documents(docs, cached_embeddings)
```
```python
# 검색
results = vectorstore.similarity_search("누구에게 이 가이드를 추천하는가?")
results
```
이제 이 결과를 llm에 보낼가?
## 검색된 결과를 prompt에 넣고 llm에 보내기
```python
from langchain.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
retriver = vectorstore.as_retriever()
prompt = ChatPromptTemplate.from_messages(
[
("system",
"""
You are a helpful AI talking to a human, Answer questions using only the following context.
If you don't know the answer just say you don't know, don't make it up:
{context}
"""),
("human", "{question}"),
]
)
llm = ChatOpenAI(temperature=0.1)
```
```python
from langchain.schema.runnable import RunnablePassthrough
chain = ({
"context": retriver,
"question": RunnablePassthrough(),
}
| prompt | llm
)
```
```python
chain.invoke("누구에게 이 가이드를 추천하는가?")
```
## DocumentsChain (문서를 vector에서 가져와서 처리하는 방식)
1. stuff - vector 검색에 걸린 모든 문서를 prompt에 넣어서 보낸다.
2. map reduce
3. refine
## 그림으로 설명
1. stuff

2. map reduce

3. refine

### stuff 검색 결과 문서를 prompt에 넣어서 보내자.
stuff라고 부르던데 .
이건 위 샘플에서 처리했다.
모든 문서를 단일 프롬프트에 "채우기"만 하면 됩니다. 이것이 가장 간단한 접근 방식입니다
We can use chain\_type="stuff", especially if using larger context window models such as:
128k token OpenAI gpt-4-turbo-2024-04-09 200k token Anthropic claude-3-sonnet-20240229
beautifulsoup4 패키지로 웹을 크롤링 해오고 그 데이터를 llm에 같이 넣어서 요약을 받자.
파일이 크니까. 큰모델로 하자.
### map reduce
"맵" 단계에서 각 문서를 자체적으로 요약한 다음 요약을 최종 요약으로 "축소"합니다
```python
from langchain_openai import OpenAIEmbeddings
from langchain.embeddings import CacheBackedEmbeddings
from langchain.vectorstores import FAISS
embeddings = OpenAIEmbeddings()
cached_embeddings = CacheBackedEmbeddings.from_bytes_store(
embeddings, cache_dir)
vectorstore = FAISS.from_documents(docs, cached_embeddings)
retriever = vectorstore.as_retriever()
```
vector store에서 검색을 하도록 체인을 구성
```python
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
map_doc_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""
Use the following portion of a long document to see if any of the text is relevant to answer the question. Return any relevant text verbatim. If there is no relevant text, return : ''
-------
{context}
""",
),
("human", "{question}"),
]
)
map_doc_chain = map_doc_prompt | llm
def map_docs(inputs):
documents = inputs["documents"]
question = inputs["question"]
return "\n\n".join(
map_doc_chain.invoke(
{"context": doc.page_content, "question": question}
).content
for doc in documents
)
map_chain = {
"documents": retriever,
"question": RunnablePassthrough(),
} | RunnableLambda(map_docs)
```
결과 나온 내용을 다시 마지막 prompt에 넣어서 최종 쿼리 llm에 보내기
```python
final_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""
Given the following extracted parts of a long document and a question, create a final answer.
If you don't know the answer, just say that you don't know. Don't try to make up an answer.
------
{context}
""",
),
("human", "{question}"),
]
)
chain = {"context": map_chain, "question": RunnablePassthrough()
} | final_prompt | llm
```
요청해보기
```python
chain.invoke("요약해줘")
```
### Refine
이건 직접 해보시요
문서를 순차적으로 요약하는데 기존에 요약된 것과 함께 다시 요약을 하는 방식 으로 업데이트합니다.